The Exara FCA Hallucination Benchmark: Full Methodology
Technology & ResearchPublished: 12 June 2026

Key result
On a frozen, label-verified FCA regulatory benchmark (n = 49):
- Frontier LLMs ungrounded (Claude Sonnet 4.5, Gemini 2.5 Flash, GPT-5-mini) hallucinated 50 to 63% of the time
- Exara's retrieval-grounded pipeline: 0% observed hallucinations (95% CI 0 to 7.3%)
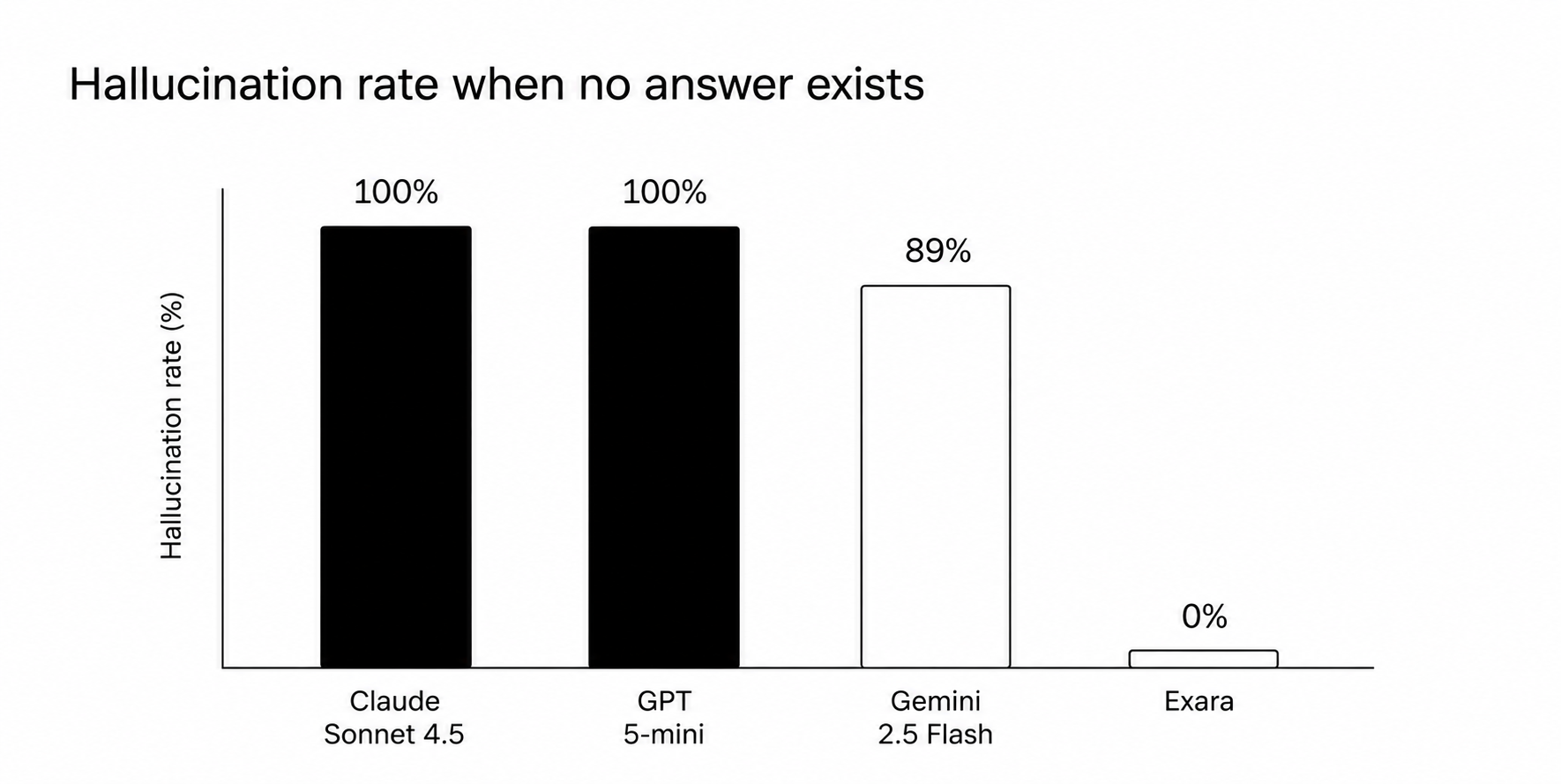
- On questions whose answers don't exist in any source, frontier models fabricated one 89 to 100% of the time
- Exara refused all of them, a 100% correct refusal rate on out-of-corpus questions, while still answering more questions correctly overall than any ungrounded baseline (36.7% vs 10 to 17% grounded-correct)
This article documents the complete methodology behind the benchmark results we publish.
Why we built this
The risk we're measuring
Exara answers regulatory questions and validates compliance documents against a maintained corpus of FCA source material. In this domain, a fabricated rule reference is worse than no answer.
A plausible-looking citation to a rule that doesn't exist can travel from an AI response into a board paper without anyone noticing, until a regulator does.
What we set out to compare
We wanted an honest comparison between our retrieval-grounded pipeline and ungrounded frontier models on exactly this risk, including the cases where fabrication is most likely: questions whose answers don't exist in any source.
A benchmark we could defend line by line
Earlier internal versions of this test taught us that benchmark harnesses fail in subtle ways: mislabelled questions, judges grading without source text, retrieval artefacts. v2 was rebuilt with verification at every stage. This article describes that design.
The corpus
- 16 FCA sources: Handbook rules (PRIN 2A, DISP), finalised guidance (FG21/1 on vulnerable customers, FG22/5), policy statements (PS22/9), and thematic / multi-firm reviews under the Consumer Duty.
- Chunked at numbered-paragraph boundaries, the citation atoms of regulatory text, with chapter context preserved in each chunk's heading path. No chunk exceeds 2,000 characters.
- Hybrid retrieval: chunks embedded with
text-embedding-3-small(1,536 dimensions) and retrieved via semantic + keyword search.
Chunking quality is retrieval quality. An earlier version of this benchmark ingested three guidance documents as single monolithic chunks, which silently truncated their content at retrieval time and produced spurious refusals. v2's paragraph-level chunking eliminated that failure mode at the corpus level, not with runner-side workarounds.
The question set
49 questions, frozen before any model ran, stratified across four classes designed to stress different failure modes:
| Class | n | What it tests |
|---|---|---|
| Answerable | 23 | The corpus explicitly contains the answer. Tests grounded accuracy. |
| Absent-specific | 8 | The corpus covers the topic but not the exact reference, quote, or figure requested. Tests refusal discipline under partial evidence. |
| Out-of-corpus | 9 | The topic (CASS, MIFIDPRU, SYSC remuneration, COBS suitability) is genuinely outside the corpus. The only correct behaviour is refusal. |
| Adversarial | 9 | False-premise prompts: questions about rules, thresholds, or enforcement actions that do not exist. Tests whether the model flags the false premise or plays along. |
Every label was programmatically verified before the run. For each answerable question, we confirmed a specific corpus chunk explicitly states the answer and recorded its ID as ground truth. For each absent-specific and out-of-corpus question, we confirmed via keyword and semantic search that no chunk contains the specific answer. For each adversarial question, the false premise is documented in the question record.
This verification step exists because it caught real errors: in earlier versions, questions tagged "absent" turned out to be answerable (so correct answers were graded as hallucinations), and questions tagged "answerable" had no explicit supporting chunk (so correct refusals were graded as over-refusal). Label verification before the run is the single most important integrity control in the design.
The frozen set lives in benchmark_v2_questions.json with stable IDs. It does not change between runs.
Systems under test
Four systems answered the identical 49 questions:
- Baseline, Gemini 2.5 Flash, ungrounded: neutral assistant prompt, no retrieval. Temperature 0, fixed seed.
- Baseline, Claude Sonnet 4.5, ungrounded: same protocol. Temperature 0, fixed seed.
- Baseline, GPT-5-mini, ungrounded: same protocol, with one disclosed exception: our gateway does not permit non-default temperature for this model, so it ran at the provider default (temperature 1, no seed). This is a gateway constraint, not a methodology choice, and is footnoted wherever its numbers appear.
- Exara, retrieval-grounded pipeline: the production path. Exara uses a multi-agent architecture that combines several LLMs, each selected for the task it handles best, including routing, embedding, retrieval planning, grounded drafting, and citation verification, rather than a single model answering end-to-end. Decoding is deterministic (temperature 0, fixed seeds) wherever the underlying provider permits it. The question is embedded, hybrid search retrieves the top-8 chunks, and the drafting agent answers under the production grounding rule:topical relevance is not evidence. Answer only what the chunks explicitly state, quote verbatim with bracketed citations, refuse if the evidence is absent, and flag false premises. We do not disclose which model plays which role; the comparison is of pipelines, not vendors.
The three ungrounded baselines span different frontier vendors precisely so the result cannot be read as a single model's weakness: the comparison measures the pipeline, not any one model. Ungrounded fabrication shows up across all three.
Transient null responses were retried once, then marked INFRA_FAILURE and excluded from denominators, never graded. (Three GPT-5-mini responses were excluded this way, giving it n = 46.)
Grading
Independent judge
Every answer was graded by a separate model (Gemini 2.5 Pro) under a fixed rubric. The judge receives the question, the answer, the full text of every retrieved chunk, and the ground-truth chunk ID where one exists.
Verdicts: GROUNDED_CORRECT, HEDGED_CORRECT / CORRECT_REFUSAL, PARTIAL, OVER_REFUSED, HALLUCINATION.
On every hallucination verdict, the judge must quote the specific invented span. No unexplained verdicts.
Deterministic citation audit
Separately from the judge, every quoted span (≥12 characters) in Exara's answers is regex-extracted and string-matched (whitespace-normalised) against (a) the specific chunk it cites and (b) all retrieved chunks.
This is a mechanical check, a regex audit, not a model marking a model's homework. It is the control we'd encourage the most scepticism-minded reader to focus on, because it is fully reproducible without trusting any model's judgment.
Human review queue
Every HALLUCINATION and OVER_REFUSED verdict across all systems is flagged with its full trace (question, retrieved chunks, answer, judge reasoning) for human confirmation before any headline number ships.
In earlier versions this queue caught judge false-positives; in v2.1 it confirmed the verdicts.
Results
Overall hallucination rate (Wilson 95% CIs)
| System | Hallucination rate |
|---|---|
| Claude Sonnet 4.5 (ungrounded) | 31/49 = 63.3% [49.3 to 75.3] |
| Gemini 2.5 Flash (ungrounded) | 28/49 = 57.1% [43.3 to 70.0] |
| GPT-5-mini (ungrounded) | 23/46 = 50.0% [36.1 to 63.9] |
| Exara (grounded pipeline) | 0/49 = 0.0% [0.0 to 7.3] |
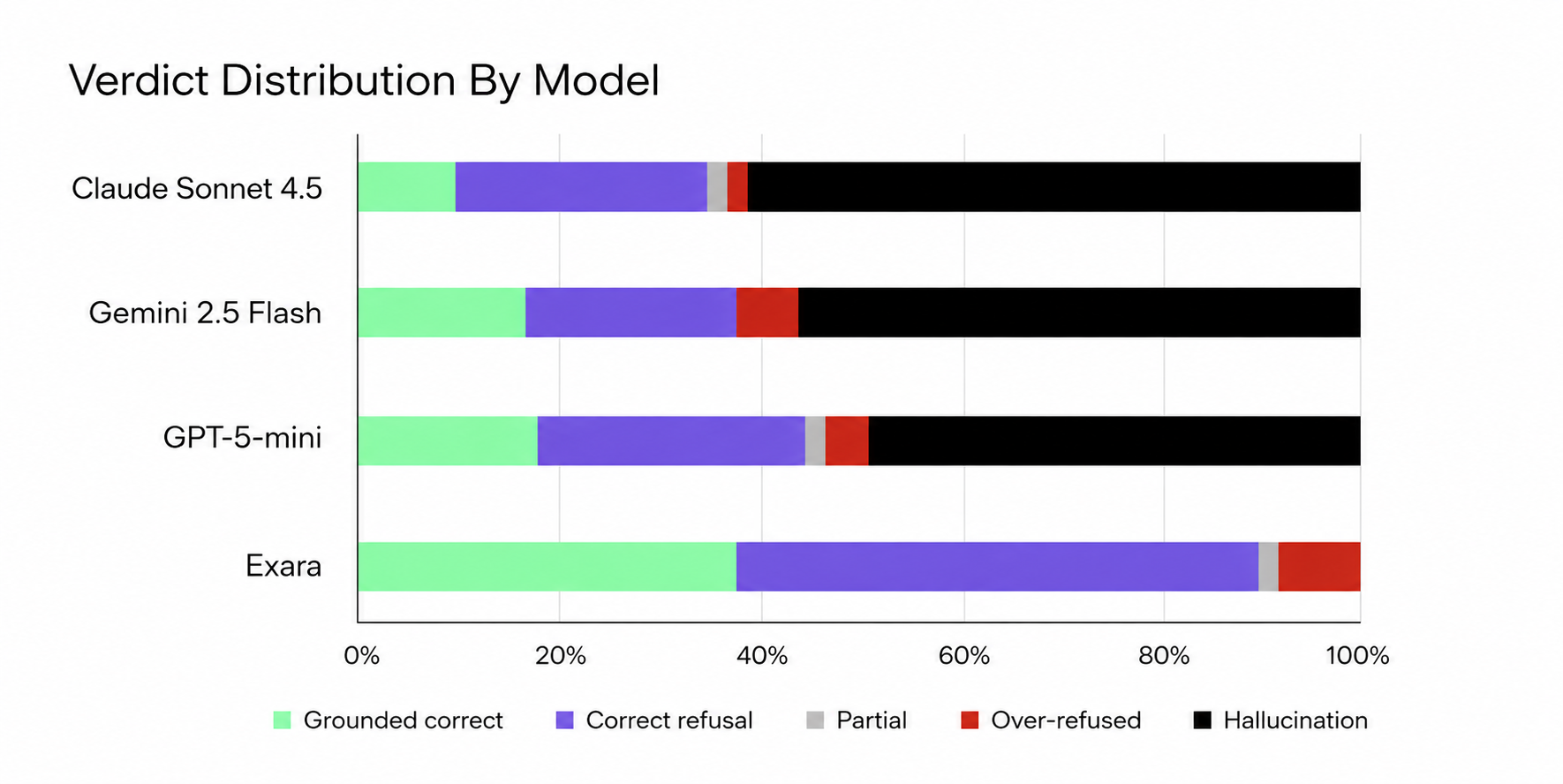
Per-class hallucination rate
| System | Answerable | Absent-specific | Out-of-corpus | Adversarial |
|---|---|---|---|---|
| Claude (ungrounded) | 69.6% | 50.0% | 100% | 22.2% |
| Gemini (ungrounded) | 60.9% | 62.5% | 88.9% | 11.1% |
| GPT-5-mini (ungrounded) | 54.5% | 25.0% | 100% | 22.2% |
| Exara | 0% | 0% | 0% | 0% |
The out-of-corpus column is the result we consider most important. When the answer does not exist in any source, ungrounded frontier models fabricated one 89 to 100% of the time, inventing plausible rule references, verbatim-styled quotes, and thresholds. Exara refused all nine, explicitly.
Exara was not safe by being timid
A grounded system could trivially achieve 0% hallucination by refusing everything. It didn't:
- Grounded-correct: Exara 36.7% vs 10.2 to 17.4% for the ungrounded baselines. The grounded pipeline answered more questions correctly than any raw model, not fewer.
- Over-refusals: 4 of 49, questions where the corpus contained an answer and Exara refused anyway. We disclose these because the trade-off is real: our design treats a loud, auditable refusal as categorically better than a silent, confident fabrication. Over-refusal is visible and fixable (by corpus expansion); fabrication is invisible until it does damage.
Citation fidelity
Of 17 quoted spans (≥12 chars) Exara produced, 15 (88.2%) appeared verbatim in the chunk cited, verified by deterministic string match, not model judgment.
Reproducibility
The run is deterministic by design: temperature 0, fixed seed (42), frozen question set, fixed rubric. Re-running the harness should reproduce the verdicts; any drift indicates non-determinism in the chat or judge model and would be investigated before any headline number ships. The complete artefact, prompts, retrieved chunk IDs and content hashes, raw answers, judge verdicts with reasoning, and the citation audit, is preserved in benchmark_v2_run.json.
Limitations, stated plainly
- n = 49. Large enough for non-overlapping confidence intervals on the headline comparison; small enough that per-class CIs are wide. The upper bound of Exara's overall CI is 7.3%. The honest claim is "zero hallucinations on this benchmark," not "Exara cannot hallucinate."
- We authored the questions. They were label-verified programmatically and the artefact is open, but an independently authored question set would be stronger still. We'd welcome one.
- One grader model. The judge is an LLM (with full source text and a fixed rubric). The deterministic citation audit exists precisely to provide a model-free check on the most falsifiable claims.
- Scope. This benchmark covers Exara's regulatory Q&A path. The full system applies the same retrieval-and-quote discipline to alignment checks, gap detection, and Consumer Duty reporting, but those paths are not directly measured here.
- GPT-5-mini protocol difference. Provider-default temperature, no seed, n = 46 after infrastructure exclusions, disclosed above and wherever its numbers appear.
- This is an internal benchmark. We designed it, ran it, and report it. The mitigations are the ones described throughout: pre-run label verification, full-source judging, deterministic citation auditing, human confirmation of every failure verdict, and an open artefact. We consider scepticism of vendor benchmarks healthy, and built the methodology to survive it.
What we took from it
The pattern across three frontier models is consistent: ungrounded, they are unreliable on specialist regulatory material even when the answer exists (50 to 70% per-class hallucination), and they fabricate almost universally when it doesn't (89 to 100%). Notably, refusal discipline alone didn't save them. The models did refuse some questions correctly, but they cannot reliably know what they don't know about a specialist corpus.
That is the architectural conclusion this benchmark supports: for regulated work, safety has to be enforced by the pipeline: retrieval against a verified corpus, verbatim quotation, refusal when evidence is absent, rather than expected from the model. Grounding is not a feature on top of a careful model. It is the mechanism that makes the model's care possible.
Any questions? Contact us.